Goal of this Exercise
In this article we will look at Java\’s
SimpleFileVisitor
as a tool to solve this problem: how to consolidate multiple backups of
data, photos, and videos, from multiple devices such as phones and
laptops. Suppose you (or your not-so-tech-savvy friends) use multiple
devices and copy files between them, and edit different versions of
those files but don\’t maintain a single \"source of truth\". How do you
get a set of unique files without manually checking each one? You could
write a shell script but for this example, we will work in Java, and
write a small program that achieves this and shows off SimpleFileVisitor
and a little of two excellent Java libraries: Google
Guava, and
picocli (ie \"pico CLI\").
We will use Guava\’s file hashing method to calculate a hash of every
file the program encounters as it traverses the file system, and use
that as an approximation for uniqueness, assuming that any two files
with the same hash are identical files. We will use picocli to make an
elegant command-line front-end for our code. The program will read in
from the command line a list of directories to traverse, and it will
traverse those directories in the supplied order. It will copy only the
first file for each hash code calculated, ignoring subsequent files with
the same hash code, to the user-supplied output directory (make sure
this directory is empty or non-existent before executing the program).
When the program is finished you will be able to call it like this (in a
Bash shell):
$ java -jar unique-merge-0.0.1-SNAPSHOT.jar \
> -o output_dir \
> first_src_dir \
> second_src_dir \
> third_src_dirand the resulting output_dir could look like this:
output_dir
|-first_dir
|-second_dir
|-third_dirDependencies
If you use a build tool such as Maven or Gradle you can easily download
the dependencies from MVN Repository:
- Guava: https://mvnrepository.com/artifact/com.google.guava/guava
- picocli: https://mvnrepository.com/artifact/info.picocli/picocli
For this example I used Gradle 6.6.1, Guava 29, and picocli 4.5.1, so my
Gradle dependencies section looks as follows:
dependencies {
compile 'com.google.guava:guava:29.0-jre'
compile 'info.picocli:picocli:4.5.1'
}Walking the File System with SimpleFileVisitor
Java\’s new file I/O package,
java.nio.file,
provides new classes and interfaces for dealing with files and
directories, including
Paths,
Path,
Files
(but not
File –
that belongs to the old I/O package), and
SimpleFileVisitor.
The SimpleFileVisitor provides a way to recurse through a directory and
its subdirectories without needing to implement a recursive method
yourself. In our example, we will walk through each directory that the
caller supplies to our program, and use Guava to calculate the hash of
each file under that directory, including sub-directories. To use the
SimpleFileVisitor, extend it, and override those methods which represent
the events you wish to intercept:
public class MySimpleFileVisitor extends SimpleFileVisitor<Path> {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { ... }
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException { ... }
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException { ... }
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException { ... }
}Note that the first two methods above have as parameters a Path and a
BasicFileAttributes,
while the last two accept a Path and an IOException, in case there was
an error while traversing the file system tree that you want to handle
before continuing. BasicFileAttributes are useful for learning about the
file\’s owner and permissions, but a proper treatment of that class is
outside of the scope of this article. Each of the methods above returns
an instance of the
FileVisitResult
enum, which determine what happens next during file system traversal.
Your options are:
| Enum | Action |
|---|---|
FileVisitResult.CONTINUE |
keep traversing the file system. |
FileVisitResult.SKIP_SIBLINGS |
don\’t examine any other files and directories within the parent of the current path object. |
FileVisitResult.SKIP_SUBTREE |
don\’t examine any other files or directories under the current Path object. |
FileVisitResult.TERMINATE |
stop traversing the file system. |
So with these things in mind, here is an example of a SimpleFileVisitor
that uses Guava to calculate the hash code of every file it traverses,
and store the hash and the file\’s path in a map. If the hash code
already exists, then the file is assumed to be a duplicate, and the
file\’s path is appended to the list of paths for that hash code,
although at present we will not use it. Later, as an exercise, you might
want to make the program print out a list of duplicate files to the
console. Using the hash code as an approximation for uniqueness is valid
for most personal use cases, whether it is suitable for industrial scale
data mining I am not qualified to comment.
package com.cheerfulprogramming.edwhiting.uniquemerge;
import com.google.common.hash.HashCode;
import com.google.common.hash.Hashing;
import java.io.IOException;
import java.nio.file.FileVisitResult;
import java.nio.file.Path;
import java.nio.file.SimpleFileVisitor;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.Deque;
import java.util.LinkedList;
import java.util.Map;
import java.util.Optional;
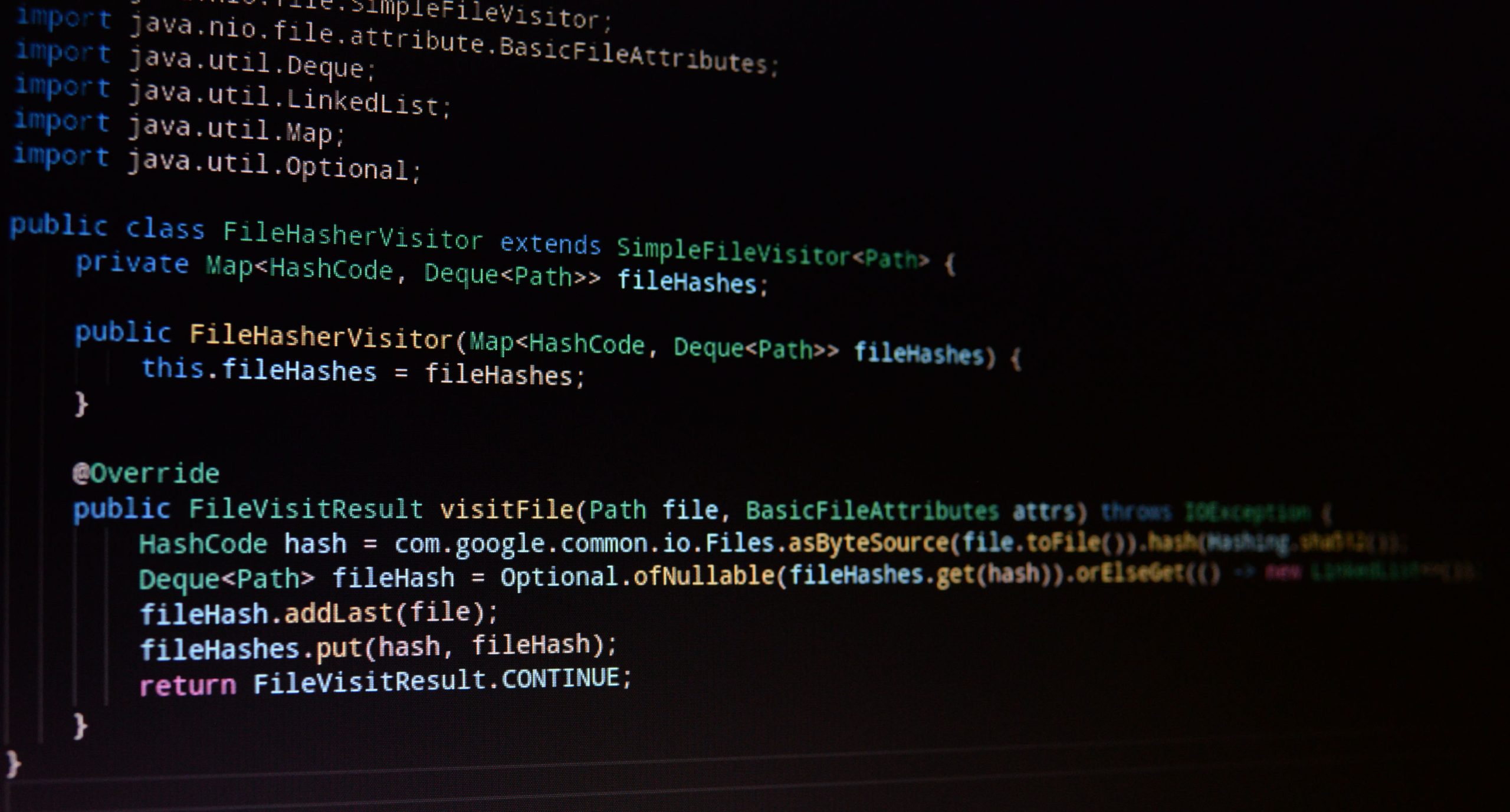
public class FileHasherVisitor extends SimpleFileVisitor<Path> {
private Map<HashCode, Deque<Path>> fileHashes;
public FileHasherVisitor(Map<HashCode, Deque<Path>> fileHashes) {
this.fileHashes = fileHashes;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
HashCode hash = com.google.common.io.Files.asByteSource(file.toFile()).hash(Hashing.sha512());
Deque<Path> fileHash = Optional.ofNullable(fileHashes.get(hash)).orElseGet(() -> new LinkedList<>());
fileHash.addLast(file);
fileHashes.put(hash, fileHash);
return FileVisitResult.CONTINUE;
}
}By itself, this class does nothing. We need to instantiate it and supply
it to a method that can traverse the file system. Fortunately, Java
provides such a method, Files.walkFileTree(Path, SimpleFileVisitor), as
shown here:
final Map<HashCode, Deque<Path>> fileHashes = new HashMap<>();
final FileHasherVisitor visitor = new FileHasherVisitor(fileHashes);
final Path path = Paths.get("path/to/your/directory");
try {
Files.walkFileTree(path, visitor);
} catch (IOException e) {
e.printStackTrace();
}Resolving Paths
Here is a more complete example, which wraps up the FileHasherVisitor
invocation in a private method called walkFileTrees, resolves relative
file system paths into absolute ones, copies only the first file for
each hash code from its source to the output directory, and exposes the
public method mergePaths, whose parameters resemble the command line
interface we are planning to build.
package com.cheerfulprogramming.edwhiting.uniquemerge;
import com.google.common.hash.HashCode;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardCopyOption;
import java.util.*;
import java.util.stream.Collectors;
public class UniqueMerger {
public void mergePaths(Path outputDir, Path... srcDirs) {
/* Get the directory from where the user called the program.*/
final Path currentDir = Paths.get(System.getProperty("user.dir"));
/*
* Resolve the output directory and source directories to absolute
* file system paths.
*/
final Path absOutputDir = currentDir.resolve(outputDir);
final List<Path> absSrcDrs = Arrays.stream(srcDirs)
.map(srcDir -> currentDir.resolve(srcDir))
.collect(Collectors.toList());
mergeAbsPaths(absOutputDir, absSrcDrs);
}
private void mergeAbsPaths(final Path absOutputDir, final List<Path> absSrcDrs) {
/* Calculate hash codes for all files under the supplied source directories. */
final Map<HashCode, Deque<Path>> fileHashes = this.walkFileTrees(absSrcDrs);
/*
* For each hash code, copy only the first file that has it,
* ignoring the duplicates.
*/
fileHashes.values().stream().forEach(fileHash -> {
final Path src = fileHash.peekFirst();
absSrcDrs.stream()
.filter(path -> src.startsWith(path))
.forEach(path -> {
final Path dest = absOutputDir.resolve(path.getParent().relativize(src));
try {
Files.createDirectories(dest.getParent());
Files.copy(src, dest, StandardCopyOption.COPY_ATTRIBUTES);
} catch (IOException e) {
e.printStackTrace();
}
});
});
}
private Map<HashCode, Deque<Path>> walkFileTrees(List<Path> absSrcDrs) {
final Map<HashCode, Deque<Path>> fileHashes = new HashMap<>();
final FileHasherVisitor visitor = new FileHasherVisitor(fileHashes);
/*
* Look at all the files under each of the supplied
* source directories, and calculate their hash codes.
*/
absSrcDrs.stream().forEach(path -> {
try {
Files.walkFileTree(path, visitor);
} catch (IOException e) {
/* Don't stop for any bad files! */
e.printStackTrace();
}
});
return fileHashes;
}
}The example above could be bundled up into a JAR with its dependencies
and made into a library, although it might not be very useful in that
form. In the next section, we will use picocli to add a command-line
interface to our program so that we can call it from a shell.
Make it Executable: Add a Command-Line Interface
Picocli is an elegant and well-documented little library that uses Java
annotations to make writing standard-compliant command line Java
programs easy.
There are many examples on the picocli website, so we\’ll only give a
brief introduction here. To start, create a class that will hold your
main method, and make it implement Runnable. Annotate it with picocli\’s
\@CommandLine.Command. Add non-static properties to your class to hold
the values of the arguments to the application. In this example, we need
a Path[] array to hold the names of the source directories, and a Path
object to hold the output directory. Picocli takes care of instantiation
for us, provided we annotate these class members correctly. See the full
example below, followed with some remarks:
package com.cheerfulprogramming.edwhiting.uniquemerge;
import picocli.CommandLine;
import java.nio.file.Path;
@CommandLine.Command(
name = "unique-merge",
mixinStandardHelpOptions = true,
version = "Unique Merge v1.0",
description = "Recursively copies supplied directories into [outputDir] " +
"directory so that only unique files get transferred, and identical duplicates " +
"do not get transferred, even if they have different names."
)
public class UniqueMergeApplication implements Runnable {
@CommandLine.Parameters(
index = "0..*",
arity = "1..*",
description = "Directories from which to copy files recursively.")
private Path[] directories;
@CommandLine.Option(
names = { "-o", "--output-dir"},
required = true,
description = "Output directory where copied directories will be placed, with only unique files.")
private Path outputDir;
public static void main(String[] args) {
final int exitCode = new CommandLine(new UniqueMergeApplication()).execute(args);
System.exit(exitCode);
}
@Override
public void run() {
UniqueMerger u = new UniqueMerger();
u.mergePaths(this.outputDir, this.directories);
}
}The @CommandLine.Parameters picocli annotation accepts many arguments
but I have only listed in the example the ones needed for this
application to work. The index argument tells picocli what position it
should expect the relevant command line arguments to be. First position
is zero, and the argument also accepts a range, eg m..n or m..* for
any position after m. The arity argument tells picocl how many values
to expect in the argument, which allows the user to pass in a list up to
a size specified by you, or of an unlimited size if you specify an open
range such as 1..*. In our example, the source directories are an array
argument of unlimited size, starting at the 0^th^ position.
The @CommandLine.Option picocli annotation allows you to specify
switches that modify the behaviour of your program, or let the user pass
in named arguments. In our example, the output directory is given as a
mandatory switch, since the source directories are an unlimited array.
Although we could have designed our application to treat the last
directory in the array of directories as the output directory, much like
the way the Unix cp program works, this way makes handling the arguments
simpler, and makes it harder for your users to do something regrettable
accidentally.
Building a JAR
There we have it, a working application! Now to build it. Below is the
Gradle build file. Make sure you have OpenJDK11 or higher installed, and
Gradle 6 with the Gradle wrapper, gradlew.
plugins {
id 'java'
}
group = 'com.cheerfulprogramming.edwhiting'
version = '1.0.0-SNAPSHOT'
sourceCompatibility = '11'
repositories {
mavenCentral()
}
dependencies {
// https://mvnrepository.com/artifact/com.google.guava/guava
compile 'com.google.guava:guava:29.0-jre'
// https://mvnrepository.com/artifact/info.picocli/picocli
compile 'info.picocli:picocli:4.5.1'
testImplementation(platform('org.junit:junit-bom:5.7.0'))
testImplementation('org.junit.jupiter:junit-jupiter')
}
compileJava {
options.compilerArgs << "-Xlint:unchecked"
}
jar {
manifest {
attributes "Main-class": "com.cheerfulprogramming.edwhiting.uniquemerge.UniqueMergeApplication"
}
from {
configurations.compile.collect { it.isDirectory() ? it : zipTree(it) }
}
}
test {
useJUnitPlatform()
}Build it with Gradle by running:
$ ./gradlew clean jarNote that in your project directory, Gradle will put the JAR in
build/libs. Execute your application like this:
$ java -jar build/libs/unique-merge-1.0.0-SNAPSHOT.jarThe program should instruct you on how to supply the correct options and
arguments, so you should then run it on the folders that you want to
merge, like this:
$ java -jar build/libs/unique-merge-1.0.0-SNAPSHOT.jar -o output_dir first_src_dir second_src_dir third_src_dirFurther Reading
Sierra, Bates, and Robson, OCP Java SE 8 Programmer II Exam Guide,
Oracle Press, 2018, pp.268, 271, 277-279, 289-292
Oracle Java API: https://docs.oracle.com/javase/8/docs/api/
Google Guava: https://github.com/google/guava
picocli: https://picocli.info/
Acknowledgements
The author acknowledges the traditional custodians of the Daruk and the
Eora People and pays respect to the Elders past and present.
Oracle® and Java are registered trademarks of Oracle and/or its
affiliates.
Google and Guava are registered trademarks of Alphabet and/or its
affiliates.